
NVIDIA сотрудничает с OpenAI для улучшения оптимизации своих новых моделей gpt-oss с открытым исходным кодом. В результате этого сотрудничества эти модели можно без проблем запускать локально на видеокартах GeForce RTX и NVIDIA RTX Pro.
Это не первый случай, когда гигант Вендор делает ставку на запуск моделей с искусственным интеллектом локально. У этого типа решений есть много преимуществ, наиболее важными из которых являются конфиденциальность, поскольку все, что мы делаем с моделями искусственного интеллекта, остается в нашей команде и в нашей компании, если мы работаем на профессиональном уровне, и независимость от сторонних поставщиков услуг.
OpenAI выпустила две новые модели: gpt-oss-20b, которая работает с 20 миллиардами параметров, и gpt-oss-120b, которая работает с почти 120 миллиардами параметров. Как многие из наших читателей, возможно, уже знают, большее количество параметров означает более точный и способный ИИ, но также повышает требования на аппаратном уровне.
Запустить модель с 120 000 параметров локально совсем непросто, помните, что до недавнего времени модели с 7 миллиардами параметров казались нам «удивительными», поэтому представьте, на что способна модель с почти в тринадцать раз большим количеством параметров.
Обе модели могут работать с до 131 072 токенами в контекстном режиме, что делает их двумя моделями с большей возможностью контекстуализации, которые существуют в настоящее время, если мы говорим о локальном запуске, очевидно.
OpenAI gpt-oss-20b разгоняется до 256 токенов в секунду на GeForce RTX 5090
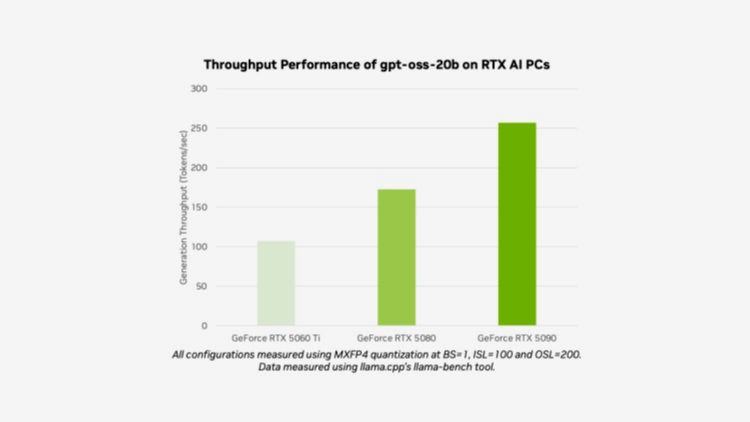
Это официальные данные о производительности, которыми NVIDIA поделилась со своим текущим лидером потребительского сегмента — GeForce RTX 5090. Рекомендуется иметь видеокарту GeForce с 24 ГБ графической памяти, но мы также можем запускать эту модель на видеокартах с 16 ГБ видеопамяти, используя MXFP4, тип точности, который позволяет использовать высококачественные модели, потребляя меньше ресурсов.
Если вы хотите протестировать модель gpt-oss-20b, которая, как мы уже говорили, может работать с 20 миллиардами параметров, самый простой и наиболее рекомендуемый способ — использовать новое приложение Ollama., который имеет полностью оптимизированную поддержку видеокарт GeForce RTX, хотя вам понадобится графический процессор с 24 ГБ видеопамяти.
На случай, если у вас нет видеокарты с 24 ГБ видеопамяти, потому что, как мы уже говорили, вы также можете протестировать эту модель на графике 16 ГБ.

Для этого вы можете обратиться к Flama.ccp, решению с открытым исходным кодом, которое поддерживается и поддерживается NVIDIA и которое вместе с библиотекой tensor GGML предлагает высокую степень оптимизации и отличную производительность с графическими процессорами GeForce и NVIDIA RTX. Еще одна очень простая и доступная альтернатива — Microsoft AI Foundry Local.
Например, используя MXFP4 с этой моделью под управлением GeForce RTX 5080, которая имеет 16 ГБ видеопамяти, мы можем получить около 170 токенов в секунду, а с GeForce RTX 5060 Ti 16 ГБ мы превысим 100 токенов в секунду.
Модель gpt-oss-120b предъявляет более высокие требования и потребляет больший объем графической памяти, что делает ее вариантом, ориентированным на видеокарты NVIDIA RTX 6000. Согласно OpenAI, эта модель может работать на видеокартах с объемом видеопамяти не менее 60 ГБ и обеспечивает эффективную работу, начиная с 80 ГБ.
NVIDIA RTX 6000 с 96 ГБ памяти GDDR7 сможет без проблем перемещать модель gpt-oss-120b локально.